很多人已经习惯把报错日志、客户反馈、聊天记录甚至数据库片段直接发给 AI 工具、论坛或工单平台,希望更快获得答案。问题在于,这些文本里往往混杂着邮箱、手机号、访问链接、API Key、账号参数等敏感信息。一旦内容被上传,后续如何存储、转发和使用,普通用户很难再完全掌控。
Privacy Filter 的出现,就是为了在“发送之前”增加一道本地检查流程。它通过浏览器端模型识别文本或截图中的敏感字段,并自动替换成占位符,让用户在保留上下文结构的同时隐藏隐私数据。相比传统手动打码或查找替换,它更适合处理复杂日志、AI 提示词和大量杂乱文本。对于开发者、客服、运营以及重度 AI 用户来说,这类本地隐私脱敏工具,可以减少分享内容时的遗漏风险,也能降低重复人工检查带来的时间消耗。
Privacy Filter 是什么?
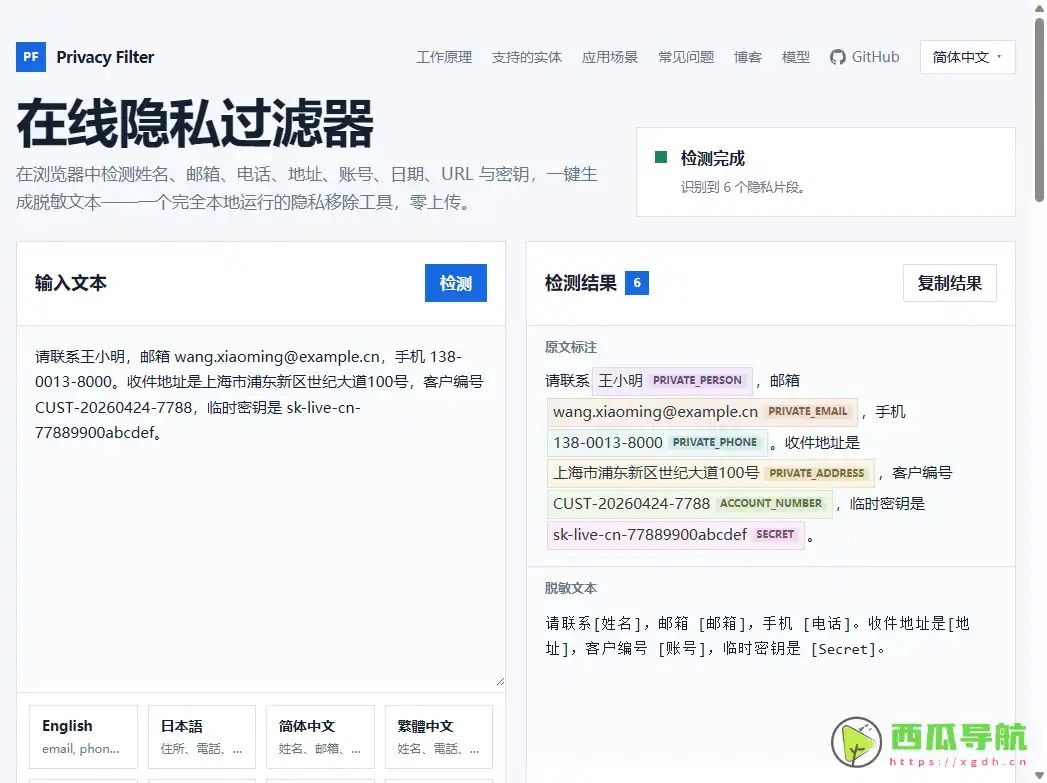
Privacy Filter 是一款运行在浏览器中的本地隐私脱敏工具,主要用于识别并隐藏文本、日志和截图中的个人敏感信息(PII)。它基于 OpenAI 开源的 privacy-filter 模型,并结合 Transformers.js 在本地浏览器环境完成推理处理。
与很多在线脱敏服务不同,Privacy Filter 并不会默认把待处理文本上传到远程服务器分析。模型首次加载后会缓存到本地,后续识别流程主要在当前设备完成。它支持识别姓名、邮箱、电话、地址、日期、URL、账号以及开发者常见的 API Key、Token 等敏感字段,同时还能通过 OCR 对截图内容进行识别和打码处理。
核心功能
Privacy Filter 的核心价值,在于帮助用户在“内容发送前”完成一次轻量级隐私检查。它更适合经常需要分享日志、截图、AI 提示词和业务文本的人群,尤其适用于开发、运维、客服和跨团队协作场景。
- 本地 PII 识别——在浏览器中检测姓名、邮箱、电话、地址等敏感信息。
- API Key 与 Token 检测——自动识别开发日志中的密钥和访问凭证。
- 文本一键脱敏——将敏感字段替换成 [EMAIL]、[KEY] 等占位符。
- OCR 截图识别——支持上传截图后自动提取文字并进行隐私过滤。
- 浏览器端运行——识别流程主要在本地完成,减少文本外发风险。
- 上下文保留——脱敏后仍能保留日志结构,方便继续排查问题。
- 多格式日志处理——适用于报错日志、工单内容、聊天记录和 AI 提示词。
- 静态部署支持——可部署到内部环境作为团队辅助工具使用。
使用场景
Privacy Filter 更像一个“发送前检查工具”。它适合那些经常需要把真实业务内容分享给 AI 工具、外部平台或协作对象的人,用来提前过滤可能泄露的敏感字段。
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| 开发者 | 提交 GitHub Issue 前清理日志中的 Token、URL 和账号参数 | ★★★★★ |
| 运维工程师 | 分享服务器报错日志时隐藏连接凭证和内部地址 | ★★★★★ |
| AI 重度用户 | 将内部文档发送给 ChatGPT 或 Claude 前做脱敏检查 | ★★★★★ |
| 客服人员 | 处理用户聊天记录时隐藏姓名、电话和邮箱 | ★★★★☆ |
| 运营人员 | 分享订单截图或反馈表单前遮盖敏感字段 | ★★★★☆ |
| 行政与人事 | 对内部文档和会议记录进行基础隐私处理 | ★★★★☆ |
| 小型团队 | 搭建内部轻量脱敏页面辅助协作 | ★★★★☆ |
操作指南
Privacy Filter 的使用流程比较直接,新手通常几分钟内就能完成第一次文本脱敏操作。
- 打开 Privacy Filter 官方页面。
- 等待浏览器首次加载模型文件(首次约下载几十 MB)。
- 在输入区域粘贴日志、聊天内容或 AI 提示词。
- 如果需要处理截图,可上传图片进行 OCR 识别。
- 点击「Analyze」或对应识别按钮开始扫描。
- 查看自动标记出的邮箱、电话、密钥和 URL 等字段。
- 点击「Redact」生成脱敏后的文本内容。
- 复制处理结果后再发送到 AI、论坛或工单系统。(建议高敏感内容再次人工复查)
支持平台
Privacy Filter 目前主要以 Web 网页形式提供服务,可在支持现代浏览器的桌面设备和移动设备中运行。Chrome、Edge 等支持 WebGPU 的浏览器处理速度会更快;部分不支持 WebGPU 的环境会退回到 WebAssembly 模式运行。截图 OCR 功能同样依赖浏览器本地能力,无需额外安装客户端。
产品定价
Privacy Filter 当前以网页工具形式提供,核心文本识别与本地脱敏功能可直接使用,整体偏向轻量化工具模式。根据公开信息,其主要功能以 免费 使用为主。若后续涉及企业部署、自定义模型或团队协作能力,仍需以官方更新说明为准。
常见问题
Q1:Privacy Filter 会把文本上传到服务器吗?
Privacy Filter 的主要识别流程在浏览器本地完成。首次打开时需要下载模型文件,后续推理通常不依赖远程文本处理。不过具体部署方式仍建议查看官方说明,并避免直接处理极高敏感数据。
Q2:它能完全替代企业级数据安全系统吗?
不能。Privacy Filter 更适合作为分享前的辅助脱敏工具,用于减少明显的敏感字段泄露。它无法替代企业级 DLP、权限控制、审计和合规体系。
Q3:识别结果一定准确吗?
模型识别会存在误报和漏报情况。面对口语化表达、特殊命名规则或自定义密钥格式时,仍可能遗漏部分内容。因此处理生产环境数据时,建议人工复查一次。
跳跳兔小结
Privacy Filter 的定位比较明确:它不是完整的数据安全平台,而是一个偏轻量化的本地隐私脱敏工具。相比传统手动查找替换,它更适合处理复杂日志、AI 提示词、截图内容和批量文本,能减少分享过程中的低级泄露风险。浏览器本地运行的方式,也降低了“为了脱敏再上传一次数据”的顾虑。
它更适合开发者、运维、客服、运营以及频繁使用 AI 工具的人群。如果你的工作里经常涉及日志分享、工单提交或跨团队协作,Privacy Filter 能帮助建立一个更稳定的隐私检查习惯。对于涉及核心商业数据、财务信息或正式合规场景的团队,则仍需要更完整的数据安全体系配合使用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...





