
在文本审核、用户评论管理或数据清洗过程中,开发者和数据分析人员常常会遇到一个现实问题:缺乏结构化、可直接使用的中文互联网敏感词数据。零散整理不仅耗时,还容易遗漏新词或变体。
ciku(中国互联网词库)正是在这样的实际需求下被整理和维护的一个开源项目。它以 GitHub 仓库的形式发布,聚焦于收集和维护中国互联网环境中常见、变化频繁的词汇类型,为文本处理、规则过滤和研究分析提供基础数据支持。
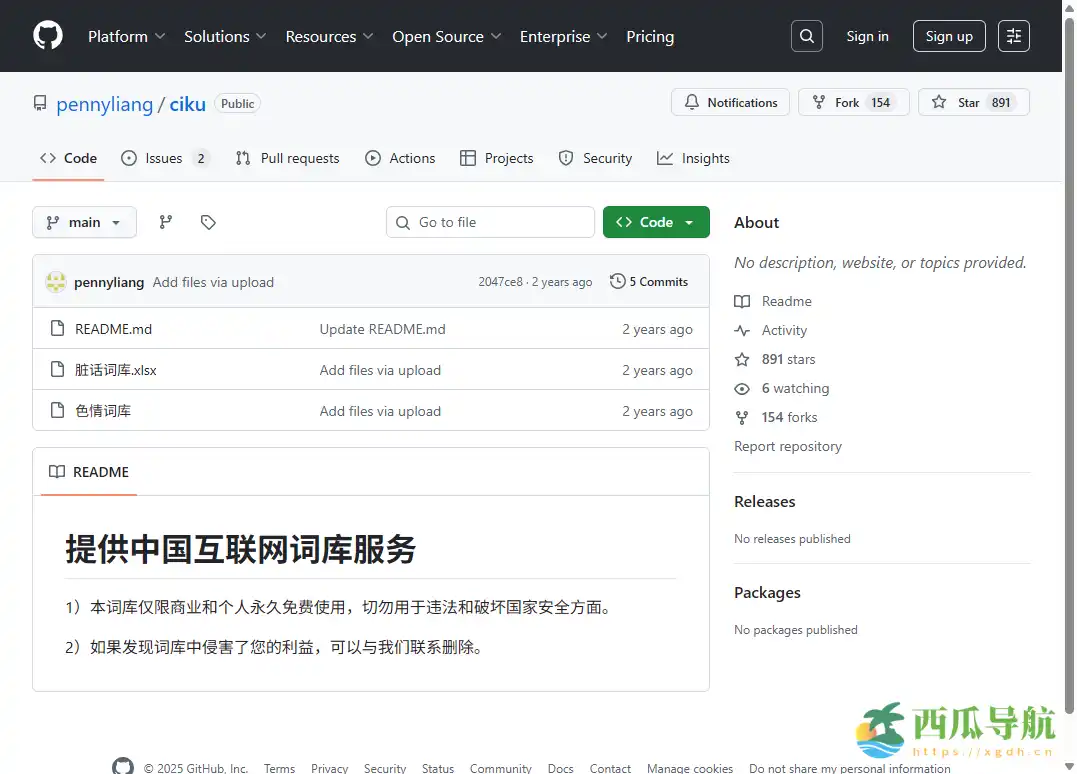
ciku 是什么?
ciku 是一个开源的中国互联网词库 GitHub 项目,核心定位是为商业和个人用户免费提供可直接使用的中文互联网词汇数据集。
目前词库重点收录的是互联网上常见的脏话词汇以及与不良内容相关的词条,主要面向内容过滤、文本预处理和数据研究等用途。项目以纯数据形式存在,不提供实际审查逻辑,强调“词库即资源”,方便开发者自行组合使用。
开源地址:https://github.com/pennyliang/ciku
核心功能
从功能角度来看,ciku 并不是一个工具或平台,而是偏向“基础数据层”的资源项目,适合用于二次开发和研究场景,主要特点包括:
- 中文互联网词库整理——集中收录常见且更新频繁的网络词汇。
- 开源数据形式——以文本文件等方式提供,便于直接引入项目。
- 免费使用授权——商业与个人项目均可免费使用。
- 易于扩展维护——可根据自身需求增删、组合或二次整理。
- 适配多种语言环境——可用于 Python、Java、Go 等程序中的文本处理。
- 学术与实践兼容——既可用于工程实践,也可用于语言研究与学习。
使用场景
ciku 的价值主要体现在“需要词表支撑的文本处理任务”中,适用范围较为明确。
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| 后端开发者 | 内容过滤、评论检测规则构建 | ★★★★★ |
| 数据分析人员 | 文本清洗与特征预处理 | ★★★★☆ |
| 产品风控相关角色 | 关键词规则补充参考 | ★★★★☆ |
| NLP 学习者 | 了解中文互联网词汇特点 | ★★★★☆ |
| 普通用户 | 日常学习与语言观察 | ★★★☆☆ |
操作指南
使用 ciku 通常不需要复杂操作,新手也可以快速上手:
- 打开 ciku 的 GitHub 项目页面。
- 浏览仓库结构,了解不同词库文件的分类。
- 通过「Clone」或「Download ZIP」下载词库。
- 根据项目需要选择合适的词库文件。
- 在代码或数据处理流程中加载词表。
- 结合正则、分词或规则引擎进行使用。
(注意:词库只提供词条本身,不包含判断逻辑,需要自行实现过滤规则。)
支持平台
作为 GitHub 上的开源项目,ciku 不依赖特定平台或系统环境。只要能够访问 GitHub 并处理文本文件,就可以在 Windows、macOS、Linux 以及各类服务器环境中使用,兼容性较强。
产品定价
ciku 明确以 免费 方式对外开放,当前词库内容对商业和个人项目均可使用,不收取费用。具体授权范围以项目仓库中的说明文件为准。
常见问题
Q:ciku 是否会持续更新?
A:更新频率取决于项目维护者和社区贡献情况,属于非商业维护模式。
Q:词库内容是否适合直接用于线上审核?
A:更适合作为参考或基础数据,线上使用建议结合多重规则和策略。
Q:是否包含完整语义或分类标签?
A:主要提供词条列表,不包含复杂语义或上下文标注。
跳跳兔小结
整体来看,ciku 是一个定位清晰的开源中文互联网词库项目,优势在于免费、可复用、覆盖面较广,适合需要进行文本过滤或数据预处理的技术用户。它并不是现成的内容审核方案,也不适合直接“即插即用”到所有场景,但作为基础数据资源,具有较高参考和使用价值。如果你的工作或学习涉及中文文本处理,ciku 能在词表层面提供有效补充。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...





