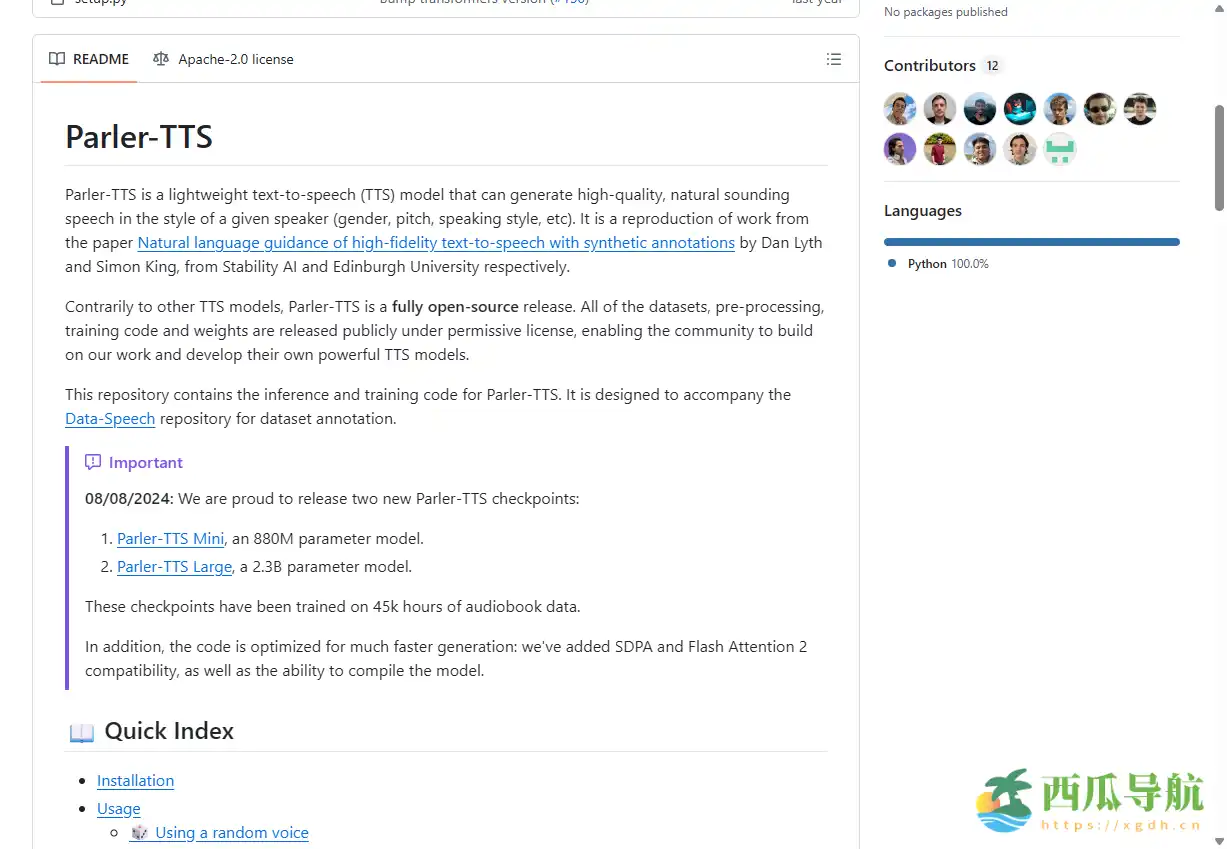
在语音合成与人机交互场景中,高质量、自然流畅的文本转语音(TTS)工具越来越受到开发者和研究者的关注。Parler TTS 提供了一个轻量级、开源的 TTS 模型,能够根据指定说话者的性别、音调和语音风格生成高保真语音。它复现了 Dan Lyth 和 Simon King 在 Stability AI 与 Edinburgh University 发表的论文成果,使用户能够以开放方式访问高质量 TTS 模型及其完整训练资源。
Parler TTS 不仅适合科研人员进行语音生成研究,也为开发者提供了可直接部署的文本转语音方案。用户可以在模型中指定多种说话参数,实现个性化语音输出。同时,模型及其训练数据、预处理流程、权重和代码均以宽松开源许可证公开,使其在教育、实验和产品开发中具有高度可用性。
开源地址:https://github.com/huggingface/parler-tts
Parler TTS 是什么?
Parler TTS 是一个轻量级的开源文本转语音模型,能够生成自然、流畅的语音,并可根据指定说话者风格调整性别、音调和说话方式。它基于 Stability AI 和 Edinburgh University 的研究成果复现,提供完整数据集、训练代码与模型权重,方便科研人员、开发者和语音技术爱好者进行二次开发、实验和集成。
核心功能
Parler TTS 面向开发者、研究者和 AI 爱好者,核心在于高质量语音生成与开放可用性。
- 个性化语音生成—— 根据说话者性别、音调和风格生成高保真语音。
- 自然流畅输出—— TTS 语音质量接近人声,自然度高,适合各类应用场景。
- 开源完整资源—— 提供数据集、预处理代码、训练流程及模型权重。
- 轻量级模型—— 相较其他 TTS 模型更易部署,适合多平台运行。
- 多场景适用—— 可用于语音助手、教育工具、播报系统、AI 内容创作等。
- 在线体验支持—— 用户可在网页端快速体验文本转语音功能。
- 灵活集成—— 可在科研实验或应用开发中调用模型 API 或本地部署。
使用场景
Parler TTS 可应用于科研、开发、教育和内容创作等多个场景,让文本信息转化为可听语音,增强互动与可访问性。
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| 开发者 | 集成 TTS 到应用、语音助手或播报系统 | ★★★★★ |
| 研究者 | 实验与语音合成技术研究 | ★★★★★ |
| 教育工作者 | 制作教材朗读或听力内容 | ★★★★☆ |
| 内容创作者 | 制作视频或音频内容的配音 | ★★★★☆ |
| AI 学习者 | 学习语音合成与模型复现流程 | ★★★★☆ |
操作指南
用户可在几分钟内使用 Parler TTS 完成文本转语音生成:
- 打开 Parler TTS 在线体验页面或下载开源代码库。
- 若使用在线体验,直接输入文本内容;若本地部署,请安装依赖环境。
- 选择说话者参数,包括性别、音调和说话风格。
- 点击「生成语音」或调用接口进行语音输出。
- 听取生成的语音,可下载或导出音频文件。
- (注意)本地部署需保证 GPU 或 CPU 计算资源足够,以保证生成速度。
- (注意)根据生成参数复杂度,处理时间可能有所不同。
支持平台
Parler TTS 可在 Web 浏览器中在线体验,同时支持本地部署在 Windows、Linux 或 macOS 系统。模型轻量,适合 GPU/CPU 计算环境,可被科研实验、教育工具及应用开发灵活调用。
产品定价
Parler TTS 是完全免费、开源的文本转语音模型,用户无需付费即可访问代码、数据和模型权重,便于学习、研究和二次开发。
常见问题
Q:Parler TTS 是否安全?
A:模型为开源项目,本身不涉及用户隐私数据存储,但在使用在线体验时请避免输入敏感信息。
Q:使用 Parler TTS 是否收费?
A:完全免费,所有数据集、训练代码和模型权重均开源。
Q:是否需要注册账号才能使用?
A:无需注册即可下载代码或在线体验文本转语音功能。
跳跳兔小结
Parler TTS 提供高质量、自然流畅的开源文本转语音解决方案,其优势在于个性化语音生成、完整开源资源以及轻量化部署。适合开发者、科研人员、教育者及内容创作者快速生成语音或进行语音合成研究。但在高并发或大规模商用场景下,可能需额外计算资源或二次优化。整体来看,它是一个灵活、可定制且易于上手的 TTS 工具。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...





