在进行网页爬取时,稳定且高效的代理 IP 是保证爬虫顺利运行的重要条件。Python ProxyPool 提供了一个完整的代理池解决方案,定期采集网络上的免费代理 IP,并进行可用性验证,确保爬虫在抓取数据时能够使用高可用的代理。项目同时提供 API 和 CLI 接口,方便开发者快速集成到爬虫系统中,并支持自定义扩展代理源。对于爬虫新手而言,Python ProxyPool 结构清晰、文档详细,是学习代理池原理和实现的良好入门工具。
Python ProxyPool是什么?
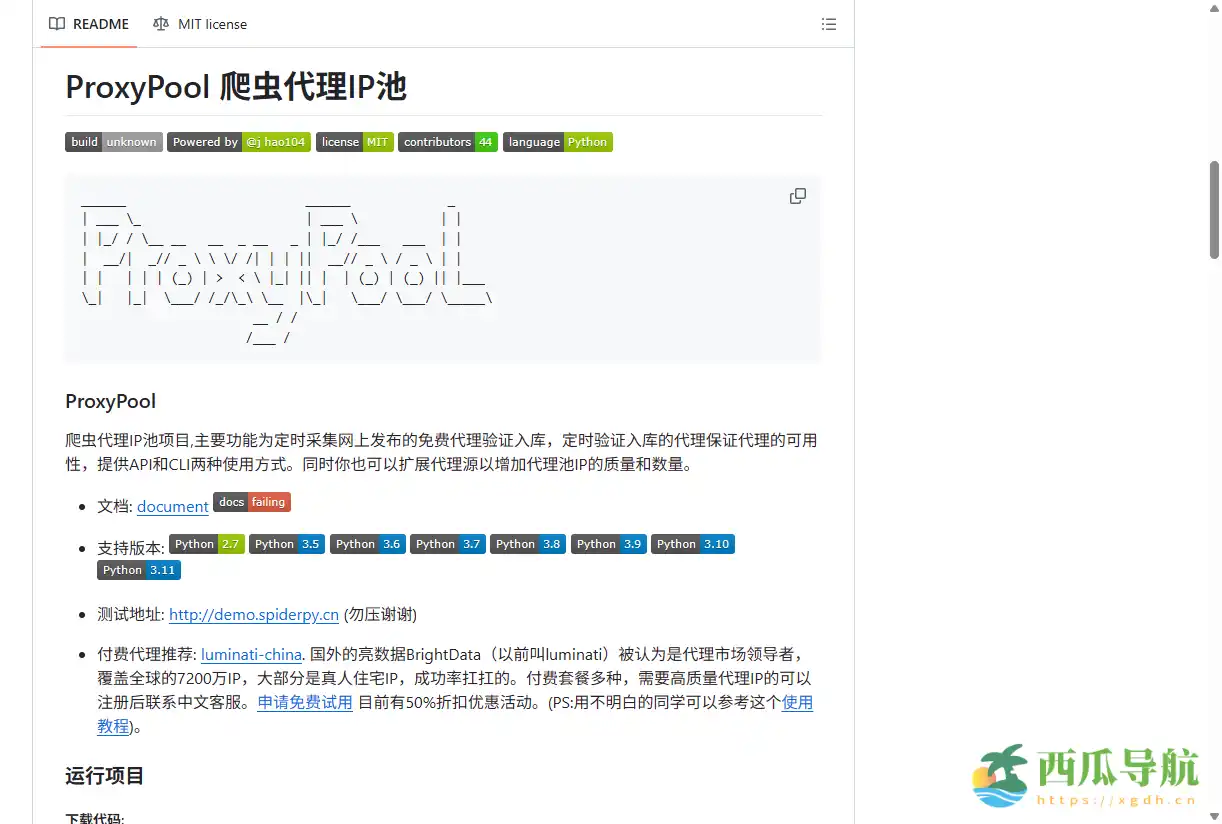
Python ProxyPool 是一个面向爬虫开发的代理 IP 管理工具,核心功能是自动采集、校验和管理免费代理 IP,并形成高可用代理池。它通过定时任务抓取网络上公开的免费代理,自动剔除不可用或响应缓慢的 IP,并提供便捷的接口供爬虫程序调用。该项目兼顾易用性与扩展性,适合新手和中级爬虫开发者学习和实践代理池相关技术。
开源地址:https://github.com/jhao104/proxy_pool
核心功能
Python ProxyPool的主要功能围绕代理采集、校验和管理设计,适合希望稳定运行爬虫的开发者使用。
- 定时采集——自动从多个公开代理源抓取免费代理 IP。
- 可用性验证——通过请求测试剔除失效或响应慢的 IP。
- 高可用代理池——保持一个可稳定调用的代理列表。
- API接口——提供 HTTP 接口,爬虫可直接获取可用代理。
- CLI命令行工具——便于本地调试和管理代理池。
- 自定义源扩展——支持添加自定义代理源,增强灵活性。
- 文档详尽——结构简明,方便新手快速上手。
使用场景
Python ProxyPool适合在多种爬虫任务下使用,帮助开发者获得稳定代理和提升爬取效率。
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| 爬虫新手 | 学习代理池原理与使用方法 | ★★★★★ |
| 数据采集者 | 爬取大量网页数据时切换 IP 避免封禁 | ★★★★★ |
| 数据分析师 | 自动化抓取公开数据接口 | ★★★★☆ |
| Python开发者 | 集成到爬虫系统中提供稳定代理 | ★★★★★ |
| 教师/学生 | 学习网络请求管理和代理原理 | ★★★★☆ |
操作指南
新手可在几分钟内搭建并使用 Python ProxyPool:
- 克隆项目至本地或下载压缩包。
- 安装依赖库(如 requests、Flask 等)。
- 配置代理源及验证参数(可使用默认配置)。
- 启动代理池服务,通过「python run.py」或「docker 启动」运行。
- 调用 API 获取可用代理,集成到爬虫请求中。
- (注意)定期更新代理池,保持 IP 的高可用性。
- (可选)添加自定义代理源以丰富 IP 池。
支持平台
Python ProxyPool 主要基于 Python,可在 Windows、Linux、macOS 等系统运行,同时支持 Docker 部署。API 可通过任何支持 HTTP 请求的语言或工具访问,灵活适配多种爬虫环境。
产品定价
Python ProxyPool为开源项目,提供免费使用,所有核心功能均可直接使用,无需付费。用户可根据需要修改和扩展源码。
常见问题
Q1:Python ProxyPool是否安全?
使用公开免费代理存在一定风险,仅在合法场景下使用爬虫,避免抓取敏感数据。
Q2:是否收费?
项目完全开源免费,无需支付任何费用。
Q3:是否需要注册或账号?
无需注册,所有功能本地即可运行。
Q4:代理池可用性如何?
通过定时验证和剔除机制,保证高可用 IP,但免费代理本身可能存在不稳定情况。
Q5:支持多语言调用吗?
API 基于 HTTP 协议,任何支持 HTTP 请求的语言均可调用。
跳跳兔小结
Python ProxyPool通过自动采集和验证免费代理 IP,为爬虫开发者提供稳定、高可用的代理资源。适合希望学习代理池原理的新手、需要大量数据抓取的开发者以及对 Python 网络请求管理感兴趣的用户。不适合需要商业级高稳定性或专用代理服务的场景。通过免费、开源、文档详尽的设计,Python ProxyPool兼具学习与实用价值。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...





