在处理复杂文档时,尤其是含有图片、公式、表格和多语言内容的 PDF、网页或电子书,传统复制粘贴方式效率低且容易出错。MinerU 提供了一款开源高质量数据提取工具,由上海人工智能实验室 OpenDataLab 团队开发,能够将多模态文档高效转化为 Markdown、JSON 等结构化格式。它具备自动识别乱码、公式转换为 LaTeX、保留文档原有结构的能力,同时支持 176 种语言识别,为学术研究、财务分析、法律文件处理等场景提供可靠的数据处理方案。
MinerU 是什么?
MinerU 是一款开源数据提取工具,专注于从复杂 PDF 文档、网页和电子书中提取高精度内容。平台支持多模态文档处理,包括文字、图片、表格和公式,并能够将结果导出为 Markdown 或 JSON 格式。其高精度解析工具链可自动识别乱码、转换公式为 LaTeX、保留文档结构,并兼容多种输入模型,适用于学术、财务、法律及其他对文档精度要求高的领域。
网站地址:https://mineru.net/OpenSourceTools/Extractor
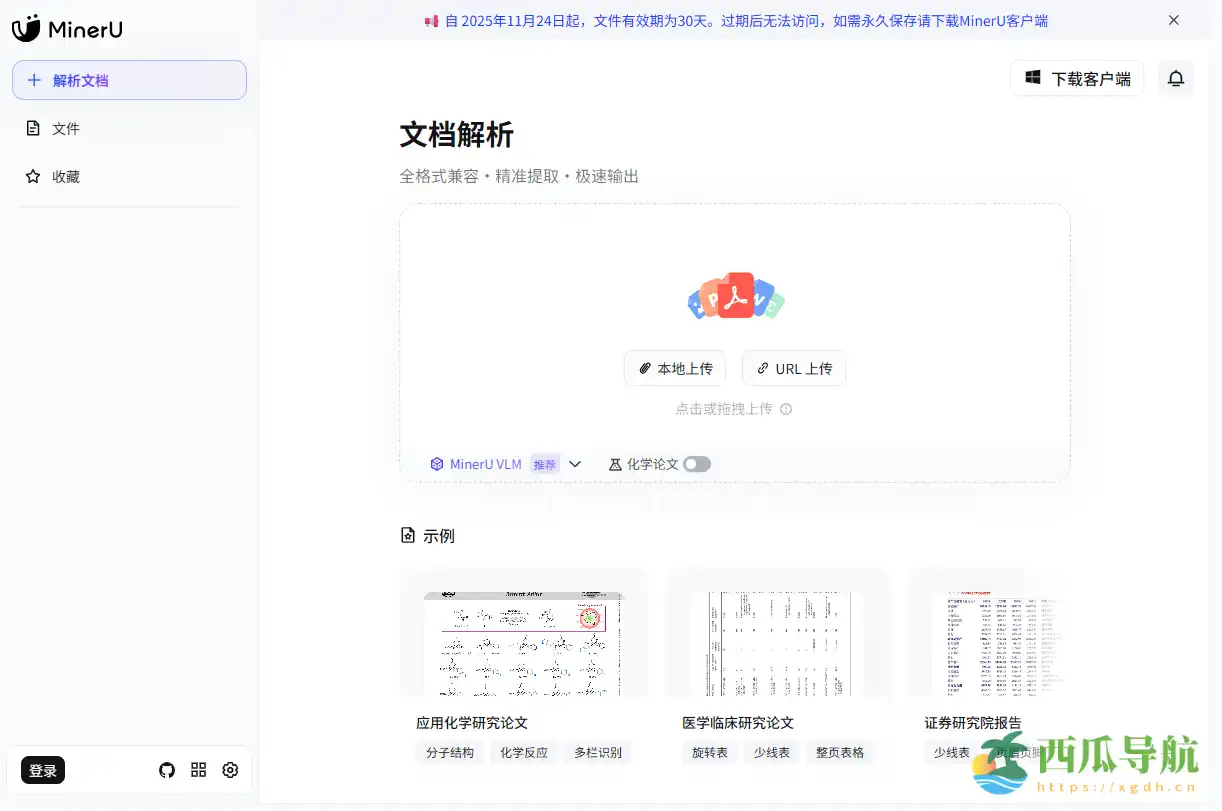
核心功能
MinerU 面向需要高效处理复杂文档的用户,提供全面的数据提取与文档结构保留功能。
- 多模态 PDF 解析——支持文字、图片、表格和公式的高精度提取。
- Markdown/JSON 导出——将复杂文档转化为结构化可编辑格式。
- 自动识别乱码——有效处理扫描或非标准编码的文档内容。
- 公式转换为 LaTeX——支持复杂数学公式和科学文档解析。
- 文档结构保留——保留原文档章节、标题、列表等布局。
- 多语言识别——支持 176 种语言,满足国际化文档需求。
- 高精度解析工具链——提供可靠的文本和表格提取能力。
- 跨平台兼容——支持 Windows、Linux、Mac 系统运行。
使用场景
MinerU 适用于学术研究、财务分析、法律文件处理及多语言文档整理等场景。
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| 学术研究者 | 提取学术论文、教材或报告中的文本和公式 | ★★★★★ |
| 财务分析师 | 分析财务报表、合同及多表格 PDF 文件 | ★★★★★ |
| 法律工作者 | 处理合同、案例文档及法规文本 | ★★★★★ |
| 内容编辑 | 将复杂文档转化为 Markdown 或 JSON 格式 | ★★★★☆ |
| 数据工程师 | 批量提取和处理网页、电子书数据 | ★★★★☆ |
操作指南
新用户可在几分钟内完成 MinerU 的文档解析流程:
- 下载 MinerU 并在本地系统(Windows/Linux/Mac)安装。
- 打开软件并选择输入文档类型(PDF、网页或电子书)。
- 配置输出格式为 Markdown 或 JSON。
- 设置是否保留文档结构及公式转换选项。
- 点击「开始解析」按钮,系统自动处理并生成结果。
- 检查导出文档,确认内容准确性和结构完整性。
- (可选)批量处理多个文档,提高工作效率。
支持平台
MinerU 支持主流桌面操作系统,确保用户在不同设备上均能高效使用:
- Windows——兼容主流版本,支持本地文件处理。
- Linux——适用于服务器或开发环境的文档解析任务。
- Mac——支持 macOS 系统用户进行高精度文档提取。
- 跨平台兼容——统一软件界面和操作体验,无需依赖云端。
产品定价
MinerU 为 开源免费 软件,用户可直接下载使用,无需支付费用或订阅。
常见问题
Q1:MinerU 是否支持公式和表格提取?
是的,MinerU 可高精度提取公式并转换为 LaTeX,同时保留表格结构。
Q2:是否需要注册账号或联网使用?
无需注册,解析过程在本地完成,不依赖服务器,保证数据安全。
Q3:是否收费或有功能限制?
核心功能完全免费,开源版本提供完整解析功能,无限制使用。
Q4:支持哪些文档类型和语言?
支持 PDF、网页、电子书等文档类型,并可识别 176 种语言。
跳跳兔小结
MinerU 适合学术研究者、财务分析师、法律工作者及数据处理人员,提供高精度、多模态文档解析服务。用户可将复杂 PDF、网页或电子书内容导出为 Markdown 或 JSON,同时保留原文档结构和公式格式。开源免费、跨平台兼容、操作灵活,适合对文档精度和结构要求较高的场景;对于仅需简单文本复制或非结构化提取的用户,其功能可能显得专业过剩。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...





