在人工智能和大语言模型(LLM)应用快速发展的背景下,获取高质量、结构化的网页数据成为关键环节。传统爬虫往往在异步处理、数据清洗和结构化输出上存在瓶颈。Crawl4AI 正是为此而生——这是一款专为 LLM 设计的开源 Web 爬虫工具,旨在帮助开发者高效、合规地从网页中提取有用数据。它支持并行爬取、异步执行、自定义钩子与丰富的提取功能,可灵活嵌入到 AI 数据处理与知识增强系统中。
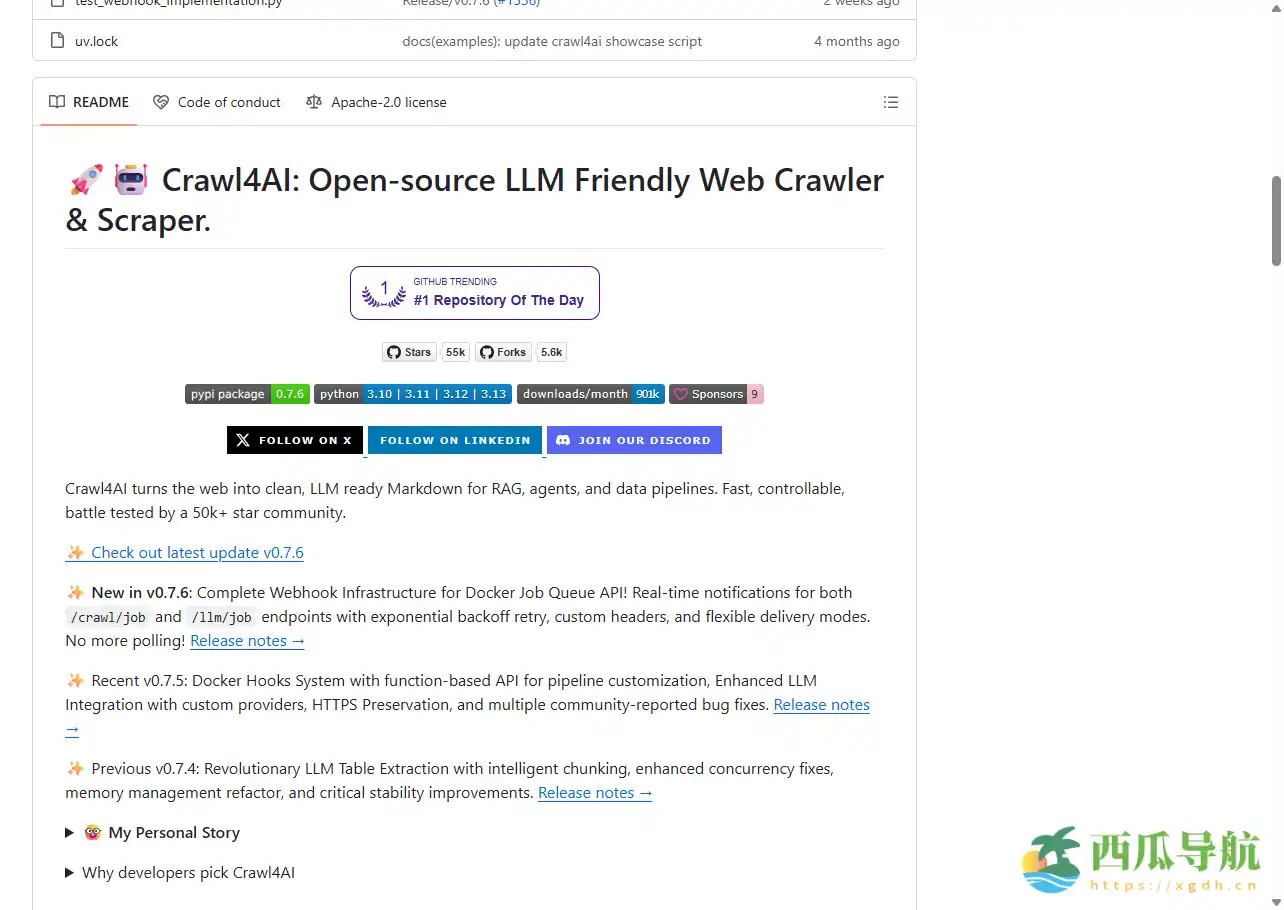
Crawl4AI 是什么?
Crawl4AI 是一个 开源、LLM 友好型的 Web 爬虫框架,专门为大型语言模型和 AI 应用程序定制。它不仅能抓取网页内容,还能自动提取文本、图片、视频、链接及元数据,输出结构化结果,便于直接用于模型训练或知识增强生成(RAG)场景。Crawl4AI 采用 异步架构,支持多 URL 并发爬取,并可通过 Python 包或 Docker 部署。其设计目标是让数据采集更智能、更安全,同时兼容各种 AI 数据管线。
开源地址:https://github.com/unclecode/crawl4ai
核心功能
Crawl4AI 将传统爬虫的抓取能力与现代 AI 场景的需求结合,提供灵活且模块化的功能组合。
- 异步并发爬取 —— 支持多站点、多页面同时抓取,提升数据采集效率。
- LLM 友好输出 —— 自动生成结构化 JSON 数据,方便直接接入 AI 模型。
- 多类型内容提取 —— 能识别文本、图片、音视频、外链、内链与页面元数据。
- 自定义钩子机制 —— 用户可注入自定义逻辑,实现特定格式或数据清洗。
- 支持 JavaScript 渲染 —— 对动态网页内容执行脚本并完整抓取。
- 用户代理与隐私控制 —— 支持自定义 UA、代理与访问速率限制,确保安全合规。
- 截图与视觉爬取 —— 可生成网页截图或捕捉视觉信息,辅助视觉模型使用。
- Docker 与 Python 双部署模式 —— 开发者可根据环境灵活选择使用方式。
使用场景
Crawl4AI 的高扩展性和结构化输出能力,使其适用于多种与 AI 相关的数据采集和预处理任务。
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| 数据科学家 | 批量采集网页数据用于模型训练 | ★★★★★ |
| AI 开发者 | 构建知识增强生成(RAG)系统 | ★★★★★ |
| NLP 工程师 | 提取网页语料用于自然语言处理 | ★★★★☆ |
| 学术研究者 | 采集学术网站内容做文本分析 | ★★★★☆ |
| 企业数据团队 | 搭建内部网页数据采集系统 | ★★★★☆ |
操作指南
Crawl4AI 提供 Python 与 Docker 两种使用方式,开发者可以在 3 分钟内完成部署。
- 安装方式一:Python 包
运行以下命令安装:pip install crawl4ai - 安装方式二:Docker 容器
使用命令:docker pull crawl4ai/crawler docker run crawl4ai/crawler - 创建爬取任务
在 Python 中导入并定义目标 URL 列表。 - 设置参数
指定并发数量、输出格式、是否执行 JavaScript。 - 运行爬取
调用crawl()方法,Crawl4AI 自动处理异步请求。 - 获取结果
输出结构化数据(JSON、CSV 或自定义格式)。 - (可选)自定义钩子
通过自定义钩子修改提取逻辑或过滤数据。
(提示:如需处理动态网页,建议启用 execute_js=True 参数。)
支持平台
Crawl4AI 支持主流开发与部署环境:
- 操作系统:Windows、macOS、Linux
- 运行环境:Python 3.8+ 或 Docker
- 集成兼容:可嵌入至 LangChain、LlamaIndex、RAG pipeline 等 AI 框架
此外,Crawl4AI 的异步设计非常适合部署在云端,如 AWS Lambda、Azure Functions、GCP Cloud Run 等。
产品定价
Crawl4AI 完全 免费开源,遵循 MIT 许可证。
用户可自由下载、修改、二次开发或集成到自己的 AI 系统中,无需商业授权费用。官方社区提供持续更新与技术支持,便于长期使用与功能扩展。
常见问题
Q:Crawl4AI 能否处理需要登录的网站?
A:支持模拟登录与 Cookie 注入,但需用户自行配置凭证与隐私策略。
Q:是否支持中文网页与多语言网站?
A:支持多语言字符集与自动编码识别,可稳定抓取中文及其他语言内容。
Q:输出数据是否可直接用于 LLM?
A:可以。Crawl4AI 的结构化输出格式(如 JSON 或 Markdown)可直接被大语言模型读取与解析。
Q:是否需要 GPU?
A:不需要,Crawl4AI 运行在 CPU 环境即可完成任务,仅在使用截图或 JS 渲染时建议启用 GPU 加速。
跳跳兔小结
Crawl4AI 是一款面向 AI 时代的智能 Web 爬虫工具,凭借 异步架构、高可定制性与结构化输出 特点,为开发者提供了高效、安全的网页数据采集方案。它尤其适用于需要构建 RAG 系统、AI 语料库、知识图谱或数据分析平台 的技术团队。
对于初学者而言,Crawl4AI 的使用门槛较低;对于进阶开发者,它的钩子机制与容器化支持提供了极大的灵活度。如果你正在为大模型构建数据源或开发自动化采集系统,Crawl4AI 是一个值得深入探索的开源解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...





