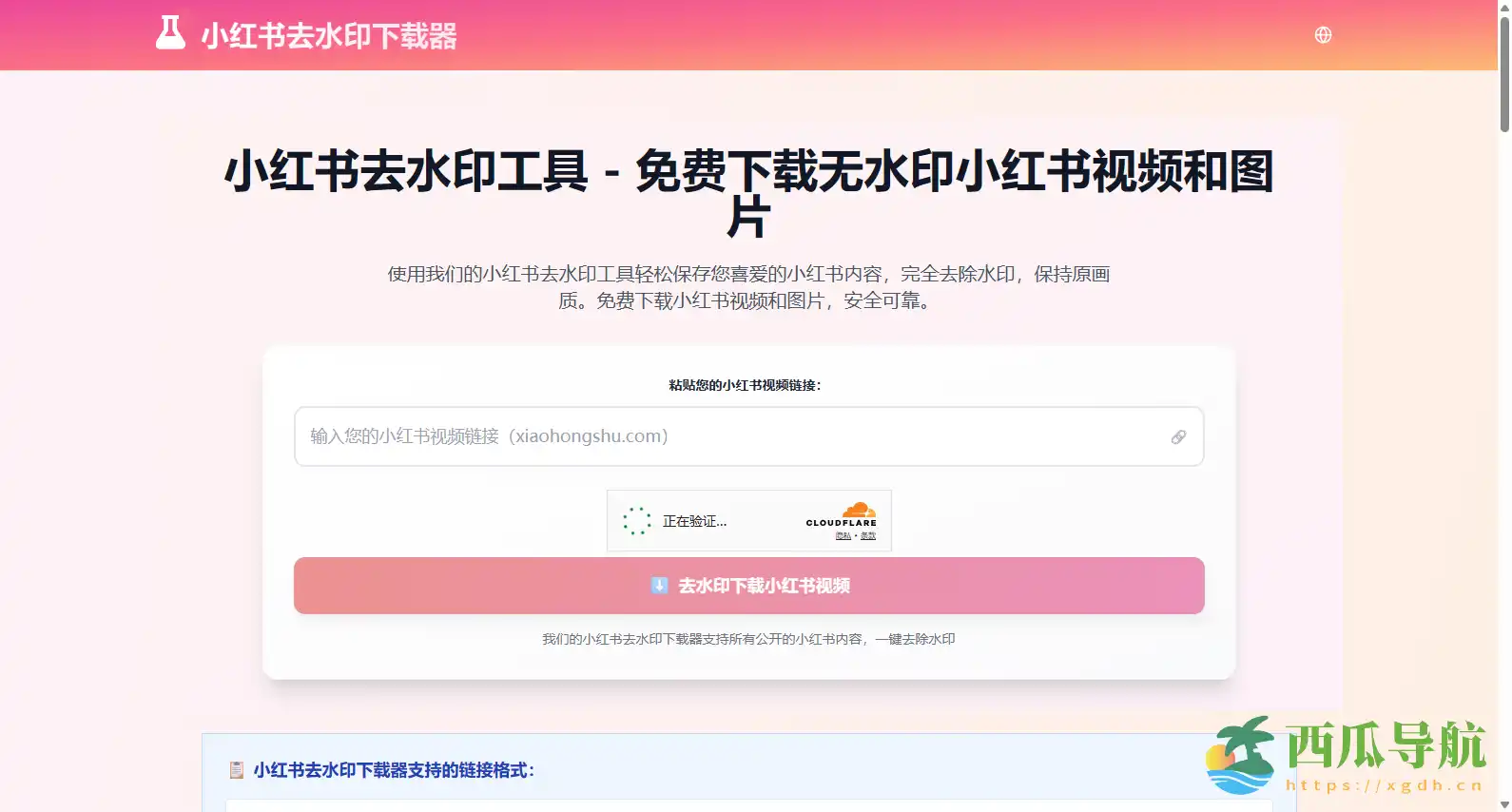
语音质量对于语音识别、视频会议、播客制作等应用至关重要,但现实环境中的噪声与混响常常影响音频清晰度。为了帮助开发者和研究人员高效解决这一问题,ClearerVoice-Studio 提供了一套功能完善的开源 AI 语音处理平台。它集成了语音增强、语音分离与目标说话人提取等关键能力,既可作为科研实验框架,也能直接支持语音类应用的开发与优化。
ClearerVoice-Studio 是什么?
ClearerVoice-Studio 是一个开源的 AI 语音处理工具包,聚焦于语音信号质量的提升与分析。项目基于现代深度学习模型开发,覆盖从噪声抑制到说话人识别的多种场景。它为语音研究人员、AI 开发者以及音频处理工程师提供了高效、可扩展的框架,帮助快速构建和测试语音处理方案。
开源地址:https://github.com/modelscope/ClearerVoice-Studio
核心功能
ClearerVoice-Studio 通过模块化设计,使用户能够根据需求灵活调用或组合功能组件。其主要功能包括:
- 语音增强 —— 自动去除噪声与回声,提升语音清晰度与听感质量。
- 语音分离 —— 将多说话人音频分离成独立轨道,便于后续识别或编辑。
- 目标说话人提取 —— 根据样本音频提取特定人物的语音,适用于会议录音或采访处理。
- 预训练模型集成 —— 内置多种先进模型,可快速加载使用或进行微调。
- 算法可视化与调试工具 —— 便于研究人员分析模型性能、优化参数。
- 多任务处理支持 —— 可同时执行多种语音任务,适用于批量数据处理。
- 插件式架构 —— 支持自定义模块扩展,方便社区开发者贡献新算法。
使用场景
ClearerVoice-Studio 既适合科研机构进行语音算法研究,也适合企业和个人开发者构建高质量语音应用。以下是典型使用人群及场景示例:
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| 音频工程师 | 对录音素材进行噪声抑制与语音优化 | ★★★★★ |
| AI 研究人员 | 实验语音分离或说话人识别模型性能 | ★★★★★ |
| 播客/视频创作者 | 改善录音音质,提取清晰人声 | ★★★★☆ |
| 企业开发者 | 集成语音增强 API 于语音通话系统 | ★★★★☆ |
| 教育与科研机构 | 用于语音算法教学与实验 | ★★★★☆ |
操作指南
ClearerVoice-Studio 提供命令行与图形界面两种使用方式,新用户可在数分钟内上手:
- 访问 GitHub 页面并下载项目源代码。
- 按说明安装所需依赖(Python、PyTorch 等)。
- 打开「config.yaml」文件配置语音模型与参数。
- 在命令行中运行「python main.py –mode enhance」启动语音增强任务。
- 导入音频文件至「input」目录,输出结果将保存在「output」文件夹。
- 若需可视化分析,可运行「analyzer.py」查看波形和频谱变化。
- (可选)启用「plugin」模块以加载自定义算法。
- 完成处理后可直接播放或导出优化语音文件。
(注意:首次运行可能需要下载预训练模型,建议确保网络稳定。)
支持平台
ClearerVoice-Studio 支持 Windows、macOS 与 Linux 系统,可在桌面端及云服务器环境运行。项目完全开源,用户可自由部署于本地或集群环境。若配合 GPU 硬件,可显著提升模型处理速度。
产品定价
ClearerVoice-Studio 为 完全免费 的开源项目,遵循 MIT 许可协议。用户可自由下载、修改与分发源代码,无需额外费用。对于企业用户,可在遵守协议的前提下集成至商业产品。
常见问题
Q1:ClearerVoice-Studio 是否需要联网使用?
A1:初次使用时需联网下载模型文件,之后可离线运行,所有处理在本地完成。
Q2:是否支持自定义模型?
A2:支持。用户可加载自训练模型或微调官方预训练模型,满足特定语音任务。
Q3:处理语音文件会上传到服务器吗?
A3:不会。所有处理均在本地进行,不涉及云端上传,保障数据隐私安全。
跳跳兔小结
ClearerVoice-Studio 以开源的方式为语音处理提供了完整解决方案,兼具科研深度与实际应用价值。它适合追求高质量音频输出的开发者、研究人员及创作者,同时也为学习语音 AI 的初学者提供了直观的平台。不适合完全零编程基础的用户直接操作,但对于具备基础技术能力的人群来说,它是一款极具潜力的语音增强与分离工具。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...





