在科研、技术报告和财务报表等场景中,PDF 与图像文档往往包含复杂表格、多栏排版和跨页内容。传统 OCR 工具在处理复杂结构时容易出现顺序错乱、表格缺失或页眉页脚干扰,导致信息整理效率低下。OCRFlux 提供了一款轻量级、多模态大语言模型驱动的工具,能够高精度地将 PDF 和图像文本转换为结构化 Markdown 格式,同时自动处理复杂布局、数学公式、跨页表格及段落合并,实现高效文档解析和内容重用。
OCRFlux 是什么?
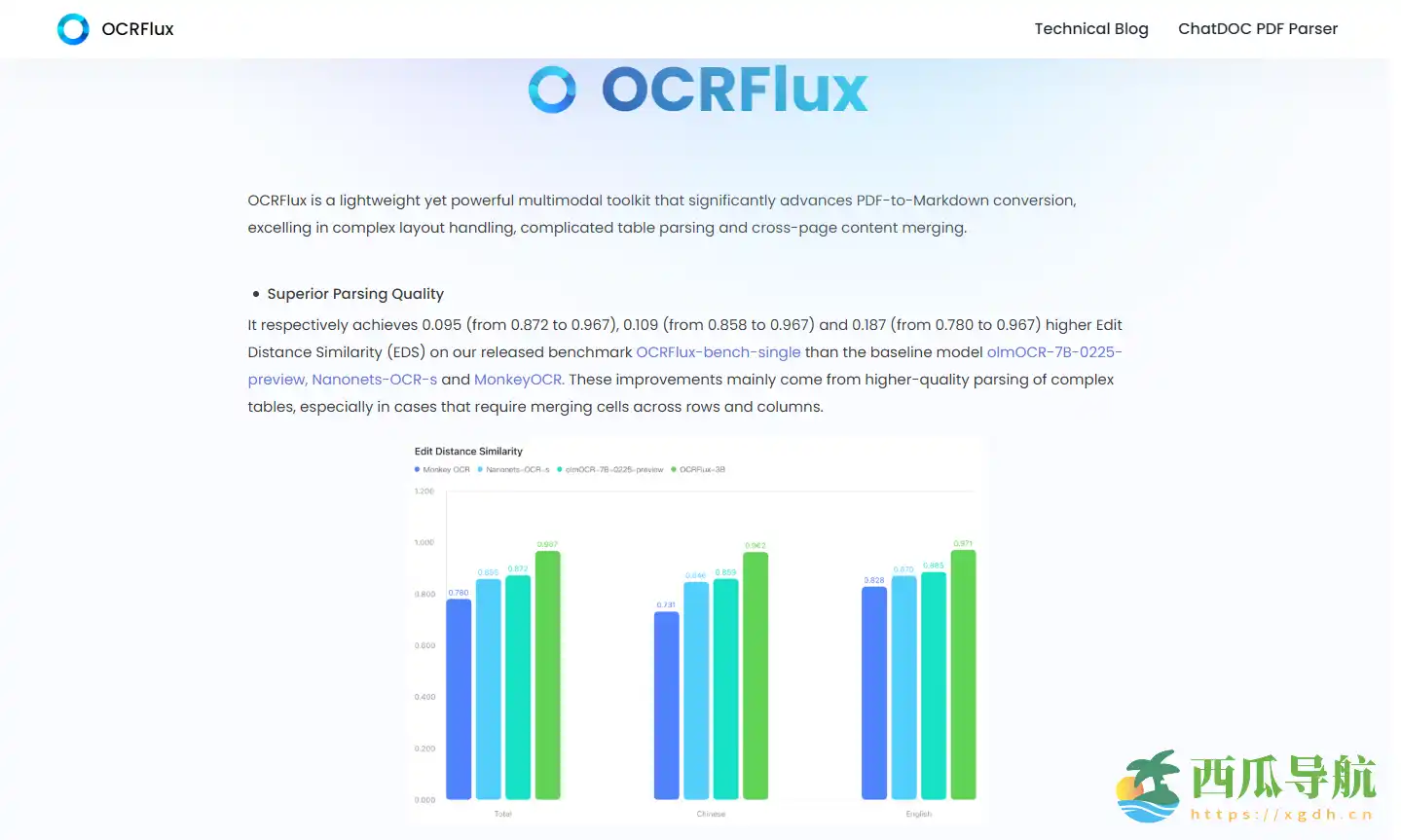
OCRFlux 是一款面向科研、教育及企业文档处理需求的开源 PDF/图像解析工具。它基于多模态大语言模型,能够自动识别自然阅读顺序的文本、多栏排版及图文混排内容,同时支持复杂表格和数学公式解析。工具设计轻量高效,模型参数仅 30 亿(3B),兼顾解析精度与速度,在 GTX 3090 GPU 上处理效率比 70 亿参数模型快约三倍。
网站地址:https://ocrflux.pdfparser.io
核心功能
OCRFlux 面向科研人员、数据分析师及文档工作者,核心功能包括:
- 全文解析——自动识别自然阅读顺序文本,适配多栏排版和图文混排。
- 复杂表格与数学公式识别——高精度解析跨行、跨列的表格和公式,确保结构完整。
- 页眉页脚剔除——自动清理冗余信息,减少文档噪声。
- 跨页表格与段落合并——原生支持跨页内容整合,输出结构连续一致。
- 高效轻量——3B 模型参数设计,在高性能 GPU 上实现快速解析,便于本地部署或集成开发。
使用场景
OCRFlux 可广泛应用于科研论文、财务报表、技术文档及各类内容密集型文档的 Markdown 转换和结构化整理。
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| 科研人员 | 将论文 PDF 转为可编辑 Markdown,方便文献整理 | ★★★★★ |
| 数据分析师 | 提取财务报表和技术报告中的表格和数据信息 | ★★★★★ |
| 教育工作者 | 整理教材或教学资料,生成结构化文档 | ★★★★☆ |
| 开发者 | 集成 OCRFlux 至文档处理工作流或二次开发 | ★★★★☆ |
操作指南
用户可快速体验 OCRFlux 的 PDF 转 Markdown 功能:
- 访问在线演示或下载 GitHub 仓库源码。
- 上传 PDF 或图像文件到平台。
- 系统自动识别文本、表格和数学公式。
- 自动剔除页眉页脚并整合跨页内容。
- 导出为结构化 Markdown 文件,保证格式连续整洁。
- (可选)将 OCRFlux 集成到本地工作流或批量处理脚本中。
支持平台
OCRFlux 提供跨平台支持,可在 Windows、macOS 和 Linux 系统上运行,并支持 GPU 加速。通过 GitHub 仓库,用户可获取源码、安装依赖或进行二次开发和自定义集成。
产品定价
OCRFlux 为 免费开源 工具,用户可自由下载、使用、修改和贡献开发,遵循开源协议,无需付费。
常见问题
Q1:OCRFlux 是否支持复杂表格和数学公式?
A1:支持,工具在跨行跨列单元格及公式识别上表现出色,解析精度显著高于常规 OCR 工具。
Q2:跨页内容能否自动合并?
A2:可以,OCRFlux 是首个原生支持跨页表格与段落合并的开源工具,准确率高达 98.3%。
Q3:模型运行是否耗费资源?
A3:工具采用 3B 模型,轻量高效,在 GTX 3090 GPU 上比 7B 模型快约三倍,同时保证高精度解析。
跳跳兔小结
OCRFlux 提供高精度、轻量级 PDF 与图像文本解析解决方案,适合科研论文、复杂报表和技术文档的结构化整理。工具在保留原始结构的同时,自动处理多栏排版、跨页表格、数学公式及页眉页脚剔除,显著提升文档转 Markdown 的效率与准确性。适合科研人员、数据分析师及文档开发者使用,但对于极大文件或非常复杂的自定义布局,仍建议进行局部校验与调整。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...





