在大型语言模型(LLM)应用日益普及的背景下,开发者与研究人员需要准确评估 API 的速度、稳定性与成本表现。LLM API Test 提供了一站式 Web 测试平台,通过实时记录首令牌延迟、每秒 Token 输出速度及成功率,让用户快速对比 GPT-4、Gemini 等主流大模型 API 的性能。工具支持多语言界面、静态托管部署,并提供质量比对与历史记录功能,适合供应商评估、应用优化及学术研究。
LLM API Test 是什么?
LLM API Test 是一款 MIT 开源 Web 工具,用于对大型语言模型 API 进行性能测试与比较。平台可适配 OpenAI(GPT-3.5、GPT-4 系列)、Google Gemini(Pro、Pro Vision)及任何兼容 OpenAI 协议的自定义端点。用户可实时监控首令牌延迟、输出速度与成功率,同时对比不同模型的响应质量。支持历史记录保存与图表可视化,便于长期跟踪模型迭代表现。
网站地址:https://llmapitest.com/?lang=zh
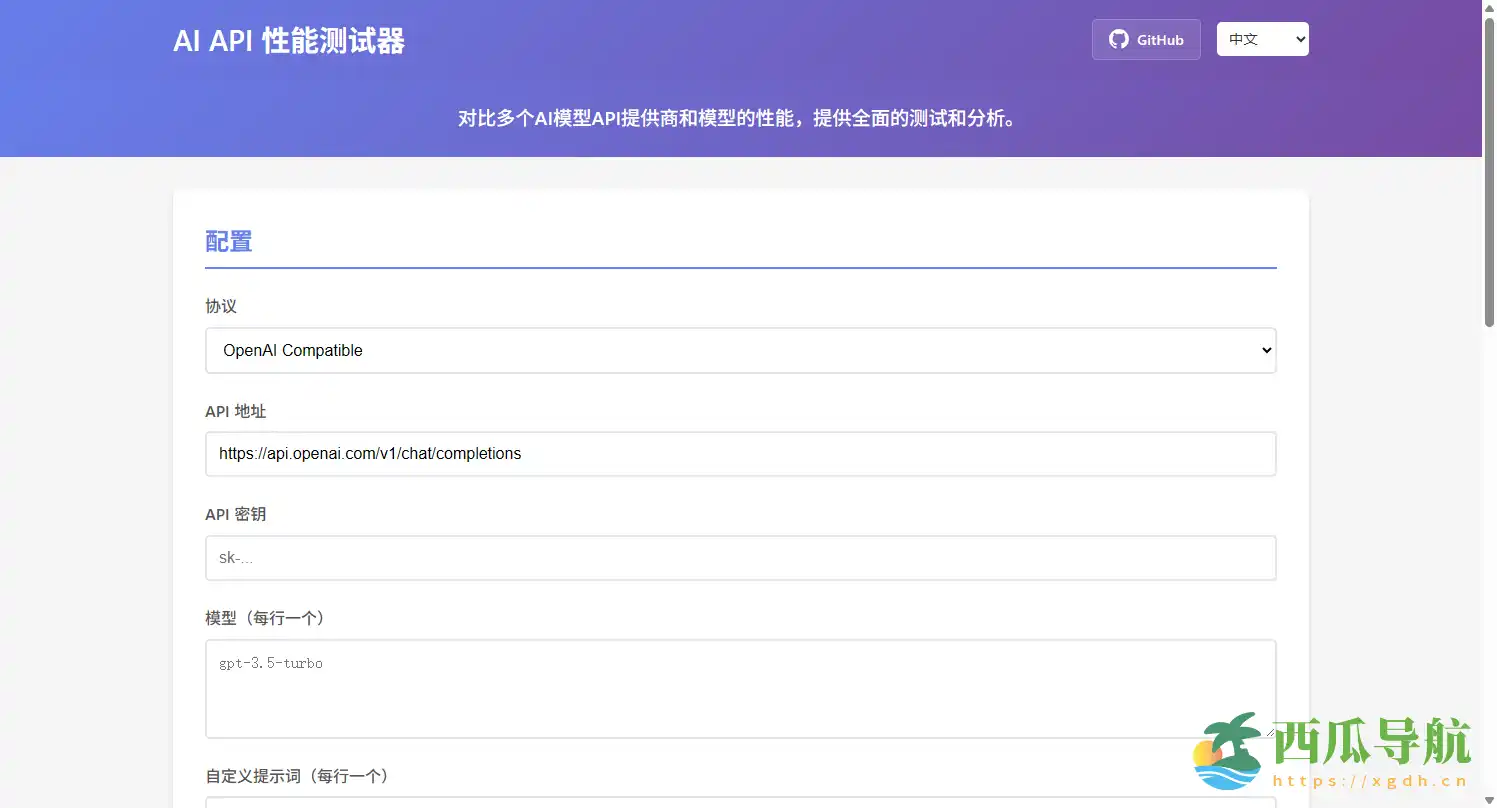
核心功能
LLM API Test 以性能基准测评和易用性为核心,适合开发者、研究人员和企业决策者。主要功能包括:
- 多模型支持——内置 OpenAI 与 Google Gemini 协议,也可接入自定义兼容端点。
- 性能指标监控——实时记录首令牌延迟、每秒 Token 输出速度及调用成功率。
- 质量评估——对比多模型响应内容,辅助判断输出准确性与可用性。
- 响应式界面——桌面与移动浏览器兼容,实时图表显示测试进度。
- 历史记录保存——便于长期跟踪模型性能变化与版本迭代。
- 灵活部署方式——支持本地 Node.js、Vercel、Netlify、GitHub Pages 等静态托管,一行 Dockerfile 快速部署。
- 自定义测试——设置测试轮次、并发度及提示词,自由调节测试参数。
使用场景
LLM API Test 可在多种实际应用中帮助用户优化模型选择与部署策略:
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| 开发者 | 比较 GPT-4、Gemini 等模型速度和吞吐量,优化应用性能 | ★★★★★ |
| 企业采购 | 对比成本、延迟及稳定性,辅助 API 供应商选型 | ★★★★★ |
| 研究人员 | 校验论文实验数据,测试模型函数调用能力与响应一致性 | ★★★★☆ |
| 教学/培训 | 演示不同 LLM API 性能指标与分析方法 | ★★★★☆ |
| DevOps | 监控 API 历史性能,优化部署和负载分配 | ★★★★☆ |
操作指南
新用户可在 5 分钟内快速上手 LLM API Test:
- 克隆仓库并安装依赖——
npm install && npm start。 - 访问本地界面——浏览器打开
http://localhost:8000。 - 配置 API——在「配置」面板选择协议,填写 API URL 与密钥,列出模型名称。
- 设置测试参数——包括测试轮次、并发度及自定义提示词。
- 开始测试——点击
Start Test即可实时查看首令牌延迟、Token/s 输出速度及成功率。 - 查看结果与历史记录——对比不同模型表现,保存数据用于分析或报告。
注意:测试过程中请确保 API 密钥权限正确,并在网络稳定环境下进行,以获得准确指标。
支持平台
LLM API Test 基于 Web,可在多终端运行:
- 桌面端:Windows、macOS、Linux 浏览器
- 移动端:iOS、Android 浏览器
- 部署方式:本地 Node.js、Vercel、Netlify、GitHub Pages 或 Docker 部署
产品定价
LLM API Test 免费 开源,MIT 协议许可,用户可自由下载、部署及修改。
常见问题
Q1:支持哪些模型?
内置支持 GPT-3.5、GPT-4 系列、Gemini Pro/Pro Vision,也可接入兼容 OpenAI 协议的自定义端点。
Q2:是否可以批量测试多个模型?
可以,支持多模型同时测试并生成比较图表。
Q3:是否保存测试历史?
支持,可长期记录首令牌延迟、输出速度和成功率。
Q4:部署是否复杂?
部署简单,本地 Node.js 即可运行,也支持静态托管和 Docker 部署。
Q5:是否支持多语言界面?
支持 7 种语言,方便全球开发者使用。
Q6:是否适合学术研究?
完全适合,可与基准测试工具(如 GenAI-Perf、MLPerf)互补使用。
跳跳兔小结
LLM API Test 是一款高效、开源且免费的 LLM API 性能测试工具,适合开发者、企业采购、研究人员及教学演示使用。平台提供多模型对比、实时性能监控、质量评估及历史记录功能,帮助用户快速做出 API 选型和优化决策。对需要精确性能分析和成本优化的用户尤其适用,但不适合仅进行单次功能调用而不关注性能指标的场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...





