在论文查找、电子书检索与学术资料获取过程中,用户经常会遇到资源分散、检索复杂、跨平台访问不一致等问题。尤其是面对跨语言文献与多类型出版物时,传统检索工具往往只能覆盖部分数据源,导致信息获取效率较低。WeLib 提供了一种以开放数据集为基础的统一检索方式,通过聚合图书与学术论文元数据,让用户能够在同一界面中快速搜索、预览与定位所需资料,从而提升文献查找与知识整理效率。
WeLib是什么?
WeLib 是一个基于 Anna’s Archive 开源数据集构建的学术资源镜像与检索平台,主要用于提供图书与论文的统一查询入口。平台整合了大规模书籍与学术论文的索引数据,并通过更现代化的网页界面优化检索体验,使用户能够更直观地浏览与筛选文献资源。
其核心定位并非单一出版平台,而是一个数据驱动的检索层工具,通过结构化元数据(如标题、作者、DOI、IS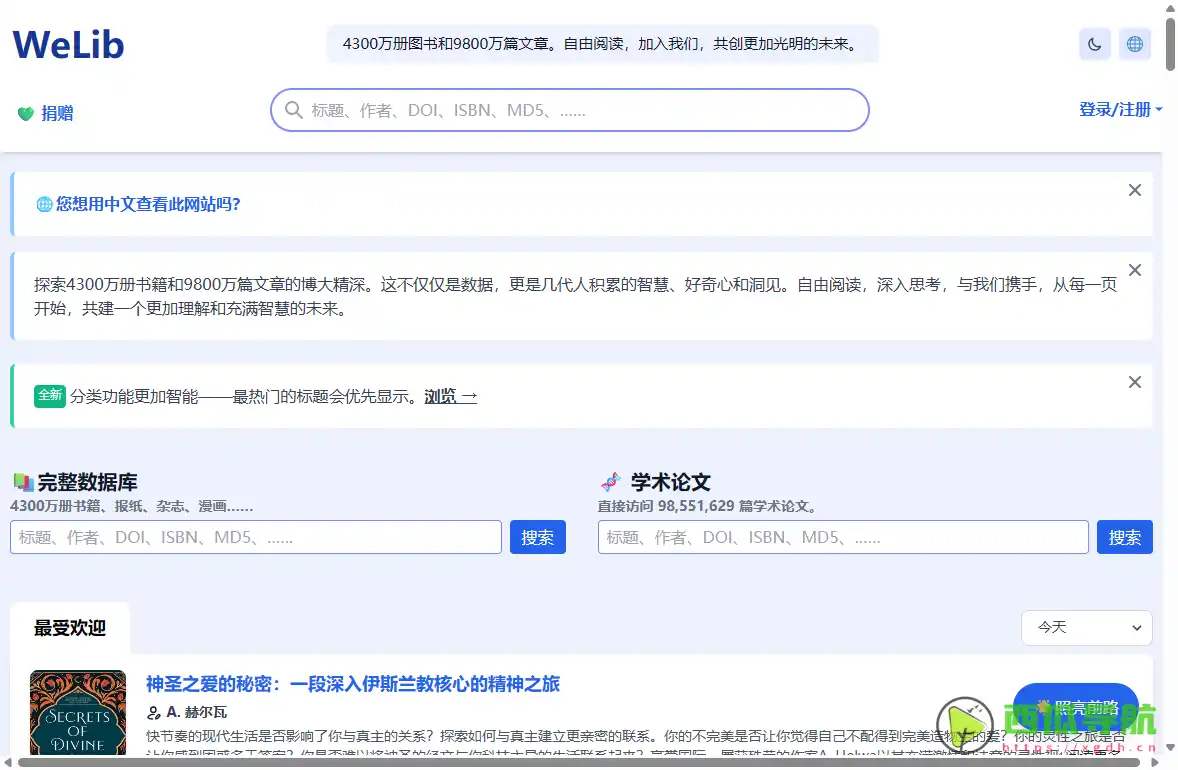 BN 等)帮助用户定位公开或可访问的学术资源。
BN 等)帮助用户定位公开或可访问的学术资源。
核心功能
WeLib 的核心价值在于“统一检索 + 结构化索引 + 快速定位”,适用于需要频繁查找文献与书籍的用户。
- **统一文献检索——**支持图书与论文混合搜索,提高查找效率
- **结构化元数据展示——**提供 ISBN、DOI、作者等字段,便于学术引用
- **大规模索引覆盖——**整合数千万级别书籍与论文数据索引
- **跨类型资源聚合——**覆盖书籍、论文、杂志与部分多媒体出版物
- **快速预览能力——**支持在检索阶段快速查看基础信息
- **多来源数据整合——**基于开源数据集构建统一访问层
- **账号体系兼容——**可与原数据体系账号体系进行一定程度联动访问(取决于数据源)
使用场景
WeLib 更适用于“检索优先”的知识获取流程,尤其在学术研究与资料整理过程中使用频率较高。
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| 学术研究者 | 快速检索论文与引用信息 | ★★★★★ |
| 学生 | 查找教材与学习资料参考 | ★★★★☆ |
| 内容创作者 | 获取背景资料与参考文献 | ★★★★☆ |
| 数据整理人员 | 批量定位出版物元数据 | ★★★★☆ |
| 普通读者 | 了解书籍信息与基础检索 | ★★★☆☆ |
操作指南
WeLib 的使用方式以搜索为核心,新用户可以在几分钟内完成基本检索流程:
- 打开 WeLib 网站首页
- 在搜索框输入书名、作者或关键词
- 浏览返回的书籍或论文结果列表
- 点击条目查看详细元数据(如 ISBN、DOI、摘要信息)
- 根据需求筛选不同类型资源(书籍 / 论文 / 出版物)
- 使用收藏或记录功能整理检索结果
- (注意:建议结合学术引用规范使用检索信息)
访问入口:
https://welib.org
支持平台
WeLib 基于 Web 架构构建,可通过主流浏览器访问使用,支持桌面端与移动端设备。用户无需安装额外软件即可进行搜索与浏览,在不同设备之间具备较好的兼容性与一致性体验。
产品定价
WeLib 当前为 免费访问模式,用户无需注册即可进行基础检索操作。部分功能可能依赖外部数据源接口,但整体使用不涉及订阅或付费机制。
常见问题
Q1:WeLib 是否是官方出版平台?
WeLib 更偏向于数据索引与检索层工具,本身不属于出版机构,而是基于开放数据集构建的镜像检索系统。
Q2:是否需要账号才能使用?
大多数情况下无需注册即可搜索与浏览内容,部分扩展功能可能涉及外部账号体系。
Q3:数据是否实时更新?
由于依赖多来源数据集,更新频率取决于上游数据同步情况,不同资源可能存在时间差。
跳跳兔小结
WeLib 更适合需要快速检索书籍与学术论文信息的用户,它通过统一索引层降低了跨平台查找成本,尤其在文献调研与资料整理场景中具有实用价值。但它本质上是一个基于数据集构建的检索工具,数据更新与覆盖范围存在一定依赖性,因此更适合作为“辅助检索入口”,而非唯一信息来源。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...





