很多人第一次折腾音视频转文字,并不是因为想做 AI 产品,而只是单纯想把会议录音、采访素材或者课程内容快速整理成文本。问题在于,长音频真正麻烦的地方,往往不是识别本身,而是时长限制。很多在线转写工具会限制免费时长;自己调用语音识别 API 时,也经常因为单次上传时长限制而失败。
voice-to-text-tools 的思路比较特别。它没有传统后端服务器,而是把音视频切片、分段处理和结果拼接这些步骤放到浏览器本地完成。用户上传长音频后,工具会自动在本地浏览器里把文件拆成多个短片段,再按照讯飞 API 的规则逐段识别,最后重新合并成完整文本。对于想自己控制转写成本、又不想额外部署服务的人来说,这类纯前端方案会更灵活。
voice-to-text-tools 是什么?
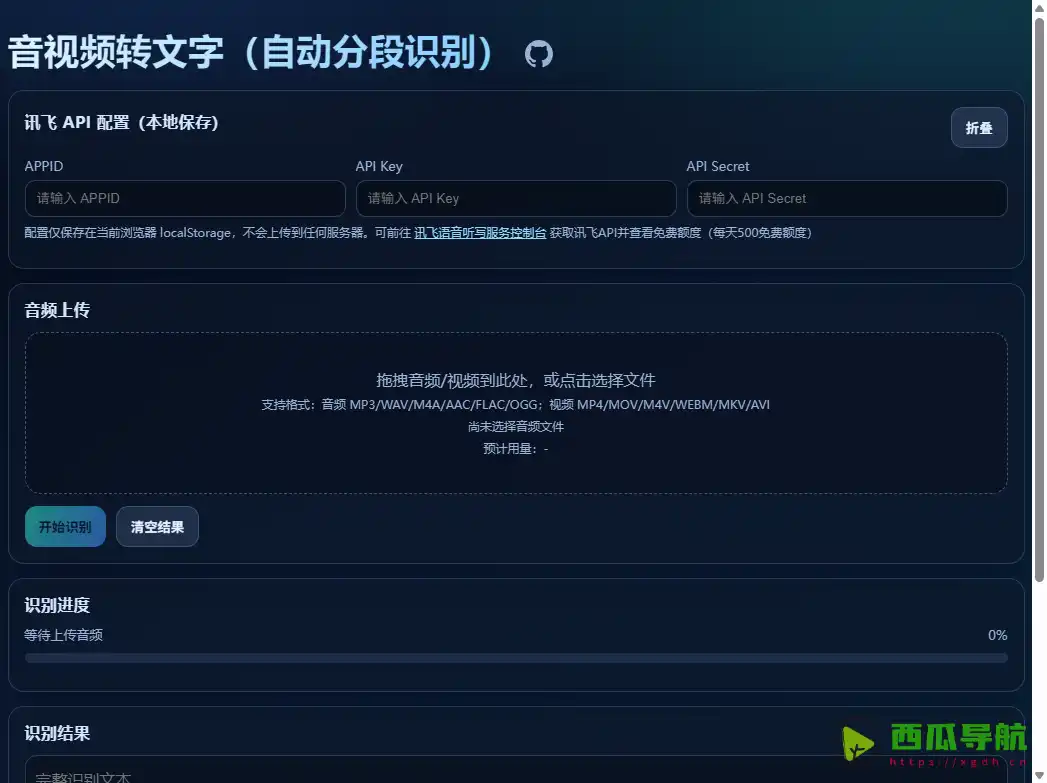
voice-to-text-tools 是一个基于浏览器运行的纯前端音视频转文字工具,主要用于长音频与视频内容的自动分段识别。
它通过 FFmpeg WebAssembly 在浏览器本地完成音视频切片,再调用科大讯飞语音识别 API 逐段转写,最后将识别结果重新拼接成完整文本。整个项目不依赖传统后端服务,可以直接作为静态网页部署到 GitHub Pages、Cloudflare Pages 等静态托管平台使用。
核心功能
voice-to-text-tools 的重点,不只是“语音转文字”,而是利用浏览器本地能力解决长音频识别的时长限制问题。
- 浏览器本地分段——自动把长音频拆分成多个短片段处理。
- 长音频转文字——适配长会议录音与课程素材识别需求。
- FFmpeg WebAssembly 处理——在浏览器本地完成音视频切片。
- 讯飞 API 对接——调用语音听写接口完成识别。
- 自动结果拼接——将多段识别结果重新合并成完整文本。
- TXT 与 Word 导出——支持导出整理后的转写内容。
- 静态网页部署——可部署到 GitHub Pages 与 Cloudflare Pages。
- 本地保存运行——无需传统服务器即可直接使用网页工具。
使用场景
voice-to-text-tools 更适合那些需要偶尔处理长音频、又希望自行控制 API 成本的用户。
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| 独立开发者 | 自行部署转写页面与管理 API 成本 | ★★★★★ |
| 内容创作者 | 转录采访、播客与视频素材 | ★★★★★ |
| 学生用户 | 整理课程录音与学习笔记 | ★★★★☆ |
| 自媒体运营 | 将长视频快速转换为文案草稿 | ★★★★☆ |
| 技术爱好者 | 研究前端 FFmpeg 与 WebAssembly 应用 | ★★★★★ |
| 普通办公用户 | 转写会议录音与访谈内容 | ★★★★☆ |
| 企业团队 | 临时处理内部录音素材 | ★★★☆☆ |
操作指南
这个纯前端音视频转文字工具需要先配置讯飞 API 凭证,整体部署与使用流程并不复杂。
- 打开 voice-to-text-tools 项目页面并下载源码。
- 将项目部署到 GitHub Pages、Cloudflare Pages 或本地静态目录。
- 前往讯飞开放平台注册并创建语音听写应用。
- 获取对应的 APPID、API Key 与 API Secret。
- 打开工具网页,在设置页面填写 API 配置。
- 上传需要转写的音频或视频文件。
- 等待浏览器自动切片并逐段识别。(长音频会更依赖本机性能)
- 导出 TXT 或 Word 文本结果保存使用。
支持平台
voice-to-text-tools 属于基于浏览器运行的纯前端项目,支持桌面浏览器环境使用。由于依赖 FFmpeg WebAssembly、本地文件处理与音视频切片能力,实际体验更适合性能较好的桌面设备。项目本身可以部署到 GitHub Pages、Cloudflare Pages 等静态托管平台,不需要额外服务器支持。
产品定价
voice-to-text-tools 本身属于开源项目,整体以 免费 使用为主。实际转写成本主要来自讯飞语音识别 API 的调用费用。根据讯飞当前公开规则,新创建应用通常会提供一定免费调用额度,后续计费方式与额度政策需以讯飞开放平台控制台说明为准。
常见问题
Q1:这个工具是真正完全离线运行的吗?
不是。音视频切片与分段处理会在浏览器本地完成,但语音识别仍然需要把音频片段发送到讯飞云端 API 解析,因此不能理解为“完全离线”。
Q2:上传的音视频会经过项目作者服务器吗?
不会。这个项目本身没有中转后端,文件切片在本地浏览器处理,识别请求直接发送给讯飞 API,不经过作者自己的服务器。
Q3:它适合企业级敏感数据转写吗?
不太适合。虽然工具本身没有后端,但音频数据仍会进入第三方语音识别服务。如果涉及高度敏感的商业会议、客户数据或合规要求,仍建议使用更严格的本地化方案。
跳跳兔小结
voice-to-text-tools 的价值,不只是“做了个转文字网页”,而是把长音频自动分段、逐段识别和结果拼接这些原本需要开发者自己处理的流程,前置到了浏览器本地完成。对于独立开发者、内容创作者和经常整理长录音的人来说,它能明显降低长音频转写的折腾成本。
不过,它更适合愿意自己配置 API、理解基础部署逻辑的用户。如果只是想拖进去直接出结果,传统商业 SaaS 工具会更省事。另一方面,“纯前端”也不等于完全离线,涉及敏感音频时,仍需要注意第三方云端识别带来的数据边界问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...





