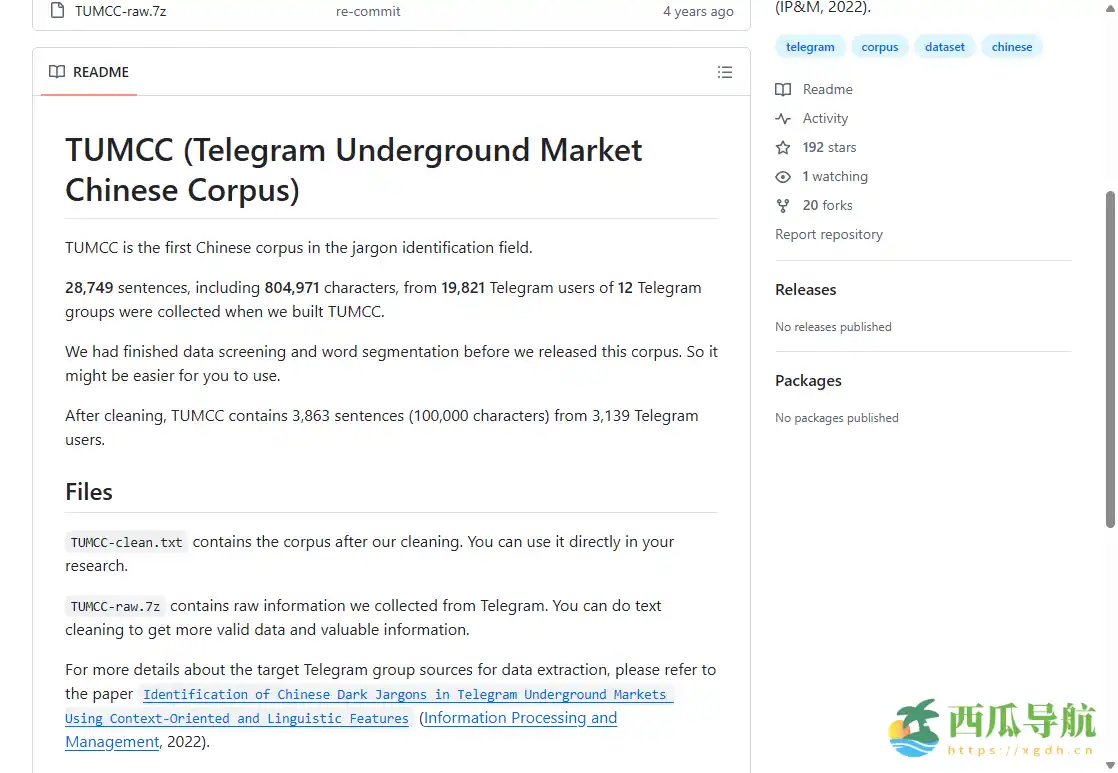
在自然语言处理与专业术语研究领域,高质量的语料库是训练模型和进行分析的基础。TUMCC提供了一份中文专业术语识别领域的语料库,汇集了来自12个Telegram群组的用户对话数据,涵盖近2万名用户和近3万条句子,总字符数超过80万。该语料库在发布前进行了数据筛选与分词处理,并提供整理后的版本,方便研究者直接使用。TUMCC适合从事中文专业术语识别、NLP模型训练和数据分析的科研人员和开发者。用户可在GitHub上访问和下载使用。
TUMCC是什么?
TUMCC(Telegram Underground Market Chinese Corpus)是一个面向中文专业术语识别的语料库,收集了12个Telegram群组中19821名用户的28749条句子,字符总数达804,971个。语料在整理发布前完成了数据筛选和分词处理,并提供整理版,方便直接用于自然语言处理、术语提取及模型训练。该语料库可作为科研和技术研究的重要数据资源。
网站地址:https://github.com/m1-llie/TUMCC
核心功能
TUMCC专注于中文专业术语研究和自然语言处理,提供清洗和结构化的数据资源。
- 中文术语数据——涵盖各类专业术语和常用表达句子。
- 用户对话语料——来自12个Telegram群组的真实对话数据。
- 数据整理——发布前完成筛选和分词处理,方便使用。
- 句子与字符统计——共28749条句子、804,971字符,可直接分析。
- 整理版本——提供结构化整理版,便于科研和开发使用。
- 开源访问——可在GitHub获取,便于下载和学习研究。
使用场景
TUMCC适用于自然语言处理研究、专业术语识别和数据分析等任务。
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| NLP研究者 | 用于术语提取、模型训练与语言分析 | ★★★★★ |
| 数据科学家 | 分析中文社交对话和用户行为模式 | ★★★★☆ |
| 学术科研人员 | 研究专业术语识别和语料库构建 | ★★★★★ |
| 开发者 | 开发中文自然语言处理应用 | ★★★★☆ |
操作指南
新用户可在 3 分钟内开始使用TUMCC语料库:
- 访问TUMCC GitHub仓库。
- 下载整理后的语料数据文件。
- 查看数据结构和文件说明,了解字段和格式。
- 导入到NLP工具或Python环境进行分析。
- 可根据研究需求进行分词、统计或模型训练。
- 遵守使用规范,仅用于科研或学习,不用于非法用途。
支持平台
TUMCC为文本语料库资源,可在 Windows、Mac、Linux 等操作系统中使用,支持Python、R等自然语言处理工具进行分析处理。
产品定价
免费开源,用户可在GitHub上下载使用,无需付费。
常见问题
Q1:是否需要注册才能下载?
A1:无需注册,GitHub上可直接下载。
Q2:语料是否经过处理?
A2:是,数据已完成筛选和分词,便于直接使用。
Q3:是否适合初学者使用?
A3:适合有一定NLP基础的用户,完全新手可能需要先学习基本处理方法。
跳跳兔小结
TUMCC为NLP研究者、数据科学家和开发者提供了丰富的中文专业术语语料资源。适合用于术语提取、模型训练和中文对话分析,不适合完全没有NLP或数据处理基础的初学者。总体来看,TUMCC通过开源、整理后的文本数据,提高了科研与开发的便捷性,为中文自然语言处理研究提供了实用资源。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...





