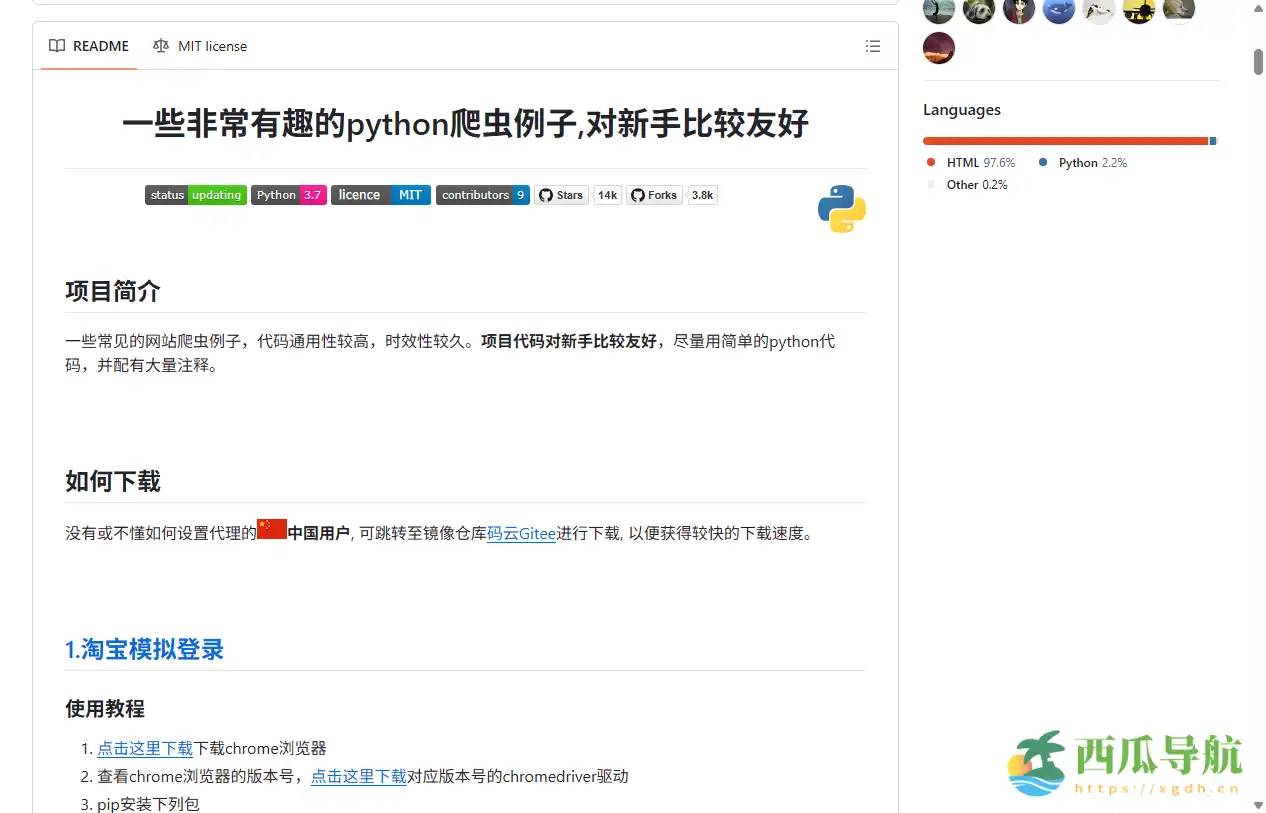
对于学习 Python 的新手来说,掌握爬虫技能是快速获取网络数据和练习编程逻辑的重要途径。examples of web crawlers 提供了多个趣味性和实用性的爬虫案例,包括淘宝、天猫、微信、微信读书、豆瓣、QQ 等网站的数据抓取示例。平台注重代码的易读性和通用性,每个案例均配有详细注释,让学习者可以轻松理解并快速上手实践。
examples of web crawlers 是什么?
examples of web crawlers 是一个汇集 Python 爬虫实例的在线学习平台。它展示了多个真实网站的数据抓取案例,案例代码通用性较高,并适合不同水平的学习者尝试。平台定位于帮助 Python 初学者学习网络爬虫技术,通过实践案例理解请求发送、数据解析和存储等核心知识点。
开源地址:https://github.com/shengqiangzhang/examples-of-web-crawlers
核心功能
examples of web crawlers 提供丰富功能和学习资源,方便用户快速掌握爬虫技术:
- 网站爬取案例——涵盖淘宝、天猫、微信、微信读书、豆瓣、QQ 等热门网站的数据抓取示例。
- Python 简单代码——使用 Python 语言编写,逻辑清晰,便于新手学习和修改。
- 大量注释——每行代码配有注释,讲解请求方法、数据解析和存储方式。
- 通用性强——示例代码可根据需求调整目标网站或数据字段。
- 持续更新——平台提供长时间维护的案例,确保代码相对稳定。
- 学习资源集中——集中展示爬虫技术、数据处理方法和代码实践技巧。
使用场景
examples of web crawlers 适合不同用户在学习、数据分析或项目开发中使用:
| 人群/角色 | 场景描述 | 推荐指数 |
|---|---|---|
| Python 初学者 | 学习爬虫基础,理解网络请求和数据解析 | ★★★★★ |
| 数据分析师 | 获取结构化数据用于分析和可视化 | ★★★★☆ |
| 项目开发者 | 实践 Python 技术,快速实现数据抓取功能 | ★★★★☆ |
| 教师/学生 | 用于课程演示和作业实践案例 | ★★★★☆ |
| 兴趣爱好者 | 探索网络数据,动手尝试抓取有趣内容 | ★★★★☆ |
操作指南
新手可在几分钟内上手爬虫案例:
- 打开 examples of web crawlers 平台网站。
- 浏览爬虫案例列表,选择感兴趣的网站示例。
- 下载或复制 Python 代码文件,确保安装所需库(如 requests、BeautifulSoup、lxml 等)。
- 阅读代码注释,理解每步操作及参数设置。
- 在本地运行代码,观察抓取结果并保存数据。
- 可根据需求修改 URL、请求头或解析规则,实现定制化抓取。
- 尝试组合不同案例进行综合练习,提高爬虫技能。(注意:遵守网站爬取规则和法律法规)
支持平台
examples of web crawlers 支持 Web 浏览器访问,用户可以直接在线浏览案例或下载代码。Python 代码可在 Windows、macOS、Linux 等环境中执行,兼容常用编辑器和 IDE,如 PyCharm、VS Code 或 Jupyter Notebook。
产品定价
平台提供 免费 学习资源,用户无需付费即可访问爬虫案例、代码示例和注释说明,适合自学和课堂教学使用。
常见问题
Q1:examples of web crawlers 是否安全?
A1:平台仅提供学习代码,不涉及敏感信息上传,安全性高。
Q2:是否收费?
A2:完全免费,无需订阅或支付。
Q3:是否需要注册账户?
A3:无需注册即可访问大部分案例,但注册后可保存收藏和笔记。
Q4:代码能直接抓取所有网站吗?
A4:部分网站有反爬机制,需要学习者适当调整请求方法或使用代理。
Q5:是否适合新手学习?
A5:适合,代码简明、注释丰富,非常适合 Python 初学者入门爬虫。
跳跳兔小结
examples of web crawlers 为 Python 学习者提供了实用且趣味性强的爬虫案例,覆盖电商、社交、书籍和娱乐等多个热门网站。平台代码通用性高、注释详尽,适合初学者练手、数据分析师获取信息以及开发者实践项目。对于希望快速掌握爬虫技术并动手实践的用户,这里提供了高效的学习路径;对希望进行大规模商业抓取或规避反爬的网站,则需要额外学习相关策略。整体而言,examples of web crawlers 是学习和练习 Python 网络爬虫的理想资源。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...





